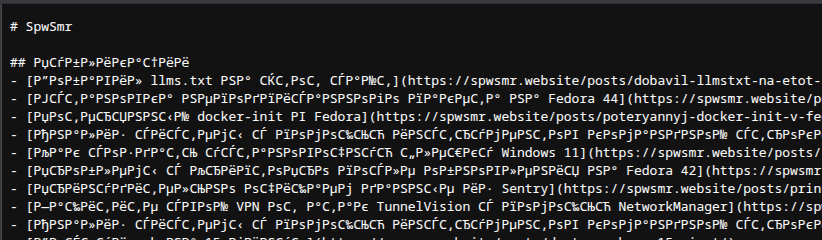
Не успел я порадоваться всему, что было сделано в рамках предыдущей статьи.
Как, проверяя новый файл, я обнаружил неприглядную картину. А именно совершенно нечитаемый контент, как показано в
баннере к этой заметке.
Поиск и диагностика#
Первым делом я, конечно, полез в DevTools браузера:

В браузере вроде бы все хорошо, но смущает одно: нигде нет данных по кодировке. На остальные страницы сайта это не
влияет из-за того, что картинки бинарные, а html имеет встроенный заголовок. Проверить заголовки, с которыми Yandex.
Cloud S3 отдает файлы можно через их cli:
1
2
3
4
5
6
7
| ❯ yc storage s3api head-object --bucket ********************* --key llms.txt
etag: '"************************947e1f8b"'
request_id: ****************
accept_ranges: bytes
content_length: "7470"
content_type: text/plain
last_modified_at: "****-**-**T**:**:**Z"
|
Да, контент тайп есть, но он без кодировки. Видимо, после упаковки в gzip и передачи через CloudFlare браузеру
“угадать” кодировку контента уже не удалось, к сожалению. А вот curl угадал:
1
2
3
4
5
6
7
8
9
10
11
| ❯ curl https://spwsmr.website/llms.txt -s | head
# SpwSmr
## Публикации
- [Добавил llms.txt на этот сайт](https://spwsmr.website/posts/dobavil-llmstxt-na-etot-sajt/)
- [Установка неподписанного пакета на Fedora 44](https://spwsmr.website/posts/ustanovka-nepodpisannogo-paketa-na-fedora-44/)
- [Потерянный docker-init в Fedora](https://spwsmr.website/posts/poteryannyj-docker-init-v-fedora/)
- [Анализ системы с помощью инструментов командной строки: free и vmstat](https://spwsmr.website/posts/analiz-sistemy-s-pomoshyu-instrumentov-komandnoj-stroki-free-vmstat/)
- [Как создать установочную флешку Windows 11](https://spwsmr.website/posts/kak-sozdat-ustanovochnuyu-fleshku-windows11/)
- [Проблемы с КриптоПро после обновления на Fedora 42](https://spwsmr.website/posts/problemy-s-kriptopro-posle-obnovleniya-na-fedora/)
- [Принудительно очищаем данные из Sentry](https://spwsmr.website/posts/prinuditelno-ochishaem-dannye-iz-sentry/)
|
Но так как файл предназначен для LLM моделей, то лучше, что бы все работало сразу и для всех.
Решение#
В GitLab CI используется образ amazon/aws-cli. И вроде бы Yandex.CLoud S3
должен быть совместим с AWS S3. Значит
нужно глянуть документацию по sync. Именно aws s3 sync используеться мной. В ней говорится, что для загрузки можно использовать --content-type "text/plain; charset=utf-8". Но тогда все файлы которые отправляются через sync будут text/plain. Это очень неудобно для
html файлов и невозможно для svg или png файлов. Значит идет по другому пути: загружаем нужный нам файл
отдельно ото всех и с ручным указанием контент тайпа. Вместо лаконичного:
1
| aws s3 sync ./public/ "$AWS_S3_BUCKET_NAME" --delete
|
будет:
1
2
| aws s3 sync ./public "$AWS_S3_BUCKET_NAME" --delete --exclude "llms.txt"
aws s3 cp ./public/llms.txt "$AWS_S3_BUCKET_NAME/llms.txt" --content-type "text/plain; charset=utf-8"
|
Да, можно было бы оба вызова сделать через sync, но пока-что файал только один и так будет нагляднее. После
обновления .gitlab-ci.yml можно насладиться результатом:

1
2
3
4
5
6
7
| ❯ yc storage s3api head-object --bucket ********************* --key llms.txt
etag: '"************************947e1f8b"'
request_id: ****************
accept_ranges: bytes
content_length: "7470"
content_type: text/plain; charset=utf-8
last_modified_at: "****-**-**T**:**:**Z"
|